推文
760 tweets · 188 sources账号:全部mattpocockukdair_aisimonwbchernyadocompletetrq212dexhorthyyetonefelixrieseberg0xblacklightdani_avila7zarazhangruiAlchainHustbadlogicgamesdoteypetergyangvikingmuteryancarsonClaudeDevskunchenguidleon7haoctatedeviamzhihuikieranklaassenmckaywrigleylennysanthdxrRhysSullivangarrytanjakevin7johnlindquistkarpathyservasyy_aitheo0xMovez9hillsRLanceMartinaidenybaidingyihylarucodermitchellhmitsuhikomvanhornomarsar0steipetezeegGeminiAppGergelyOroszZaynHaoaddyosmaniantirezdanshipperdillon_mulroyelonmuskewind_devidoubiccnummanalirealWeZZardswyxthsottiauxyiliush0xPaulius0x_rodyAYi_AInotesAnthropicAIBarret_ChinaBenJames_____CMGS1988ChadMoranDanielMiesslerDaveJDavidKPianoDimillianFactoryAIFardeemMFarzaTVGoogleDeepMindHamelHusainHiTw93HilaShmuelIfanJewIndieDevHaileyJack_W_LindseyJackywineJasonZXJiaxi_CuiJinjingLiangKhalidWarsaLinearUncleLinghuaJMatthewBermanMaxForAIMeari_V2_0_GMnilaxQingQ77RaillyHugoSaccc_cTaniyatweets_VincentLogicai_explorer25aibuilderclub_alexalbert__alliekmillerandrewfarahantoinecojpanxue201arkuy99artmanasynkimobbssppllvvbearliubentossellbridgemindaibuaaxhmcailynyongyongcgtwtscharmaine_kleechrisbarberchrisparkXclairevodelba_oliveirademishassabisdoodlesteindriaforallelithrarelvissunericzakariassonfrancoisfleuretgabriell_labiamsahaj_xyzimdigitalashishimvihvjarredsumnerjerryjliu0jianshuojiayuan_jyjlongsterjonas_nellejoshalbrechtjpschroederkaiofreitaskepanolexruslogancyangmattypnabeelnifinetninthbit_aioran_gepatrickcpejmanjohnpetradonkaprathamgrvprathyvshquanruzhuoxiuquant_sheepraroquerealCaigurepsiacerohanpaul_aisamasamuelstroscheisawyerhoodshadcnshao__mengshaogefenhaoshreyansjtechgirl1908techwith_ramthorstenballtianyitobiaswuptoddsaunderstricaltturingoututuretomuniswap12untraceable_thevanillaCitronvelvet_sharkwengtianxinwquguruxiaogaifunxicilionycombinatorzachlloydtweetsziwenxu_zodchiii
@bcherny·6月19日
Cool way to use Claude Code: deciphering Linear A, a 3500 year old written language from Crete
https://t.co/Aqd4ZG7Cum
Hope this holds up in peer review! 🤞
Claude Code 的一个有趣用法:解读 Linear A——克里特岛上一种有 3500 年历史的古文字。 希望能通过同行评审!🤞
@dexhorthy·6月19日For You
it turns out if you do a lot of really good context engineering, you can get frontier intelligence for like half the price, and in some cases even better than a single frontier model
@tomgreenwald
Introducing Magnitude. It's a coding agent that runs entirely on open models. It costs 60% less than Claude Code with no drop in performance. Try it now: npm i -g @magnitudedev/cli Here's how it works 👇 https://t.co/uPvYrHOrW8
原来如果你做了大量优质的 context engineering,可以用 frontier 级别的智能只花一半的价钱,某些情况下甚至比单一 frontier model 表现更好 > 引用 @tomgreenwald:推出 Magnitude。 > > 这是一个完全基于 open models 运行的 coding agent。 > > 比 Claude Code 便宜 60%,性能毫不逊色。 > > 立即体验:npm i -g @magnitudedev/cli
@dair_ai·6月19日
Catch up on the "loop engineering" trend in this banger article.
@omarsar0
From Prompting Agents to Loop Engineering
关注下「loop engineering」这个趋势,这篇文章写得很好。 [引用 @omarsar0]: 从 Prompting Agents 到 Loop Engineering
@mattpocockuk·6月19日
An absolute monster PRD, built out from a /decision-mapping session
Love this new flow
https://t.co/mkYXueoJPW
用 /decision-mapping session 生成了一份超详细的 PRD。 很喜欢这个新工作流。
@samuelstroschei·6月19日For You
today i'm launching Flashtype, a markdown editor for Claude & Codex
use Claude/Codex to edit markdown, track every change, and see the diffs
open source. available now. https://t.co/JtFc9m4Ae1

今天发布了 Flashtype,一款面向 Claude 和 Codex 的 Markdown 编辑器。 用 Claude/Codex 编辑 Markdown,追踪每一次改动,查看 diff。 开源,现已可用。
@Barret_China·6月19日For You
大概一个月多前,电脑中了木马,潜伏了一个月才被发现,也导致了我的 X 账号被盗。
让 Claude 和 Codex 逐一分析系统进程时,找到了一个叫做 com\.apple.accountsd.helper.plist 的进程,乍一看还以为是苹果系统的宿主进程,但 Claude 对这个进程提出了质疑。
沿着这个线索,对 accountsd 进行了详细的分析。这个木马首先给系统添加了一个开机自启项,确保可长期潜伏,然后通过 root 权限写了一个守护脚本,每秒探测当前系统是否有新用户登录,一旦登录就通过 AppleScript 脚本切换成当前用户身份,运行一个叫做 AccountsHelper 的程序。
对 AccountsHelper(SHA256:9168cbc45f)也做二进制分析,它的依赖极少,主要职责是从远端加载指令,然后拉起一个交互式 PTY shell,攻击者就是通过这个 shell 来远程操控电脑的。木马执行的每个环节,清理工作都做的特别好,几乎所有日志都被清理干净了。
为了溯源整个中马过程,我分析了将近两个多月的系统日志,仅找到一条可疑指令:有个 curl 操作,下载并执行了一条混淆命令,这也是唯一的线索,解密指令得到了一个远端 IP地址。
后来也从公开情报里找到这个木马,它是 AMOS Stealer 恶意软件家族的变种,之前主要针对 Windows 平台,今年四月第一次在 macOS 上被发现。
从 .zhistory 日志看,curl 前后都是 Claude Code 相关操作,高度怀疑就是 Agent 程序引入了这个木马。
我的 Claude Code 长期是 bypass 模式,所有的命令执行都是直接放过,怀疑是在做软件安装或更新的时候,AI 从互联网找到了一些不安全的资源,下载了这个木马。
这个 AMOS 木马,主要会去扫各种虚拟货币钱包,尤其是浏览器插件钱包。顺带也把我各种登录态 Cookies 全部拿走了,这才导致 X 账号被恶意添加了一个 Passkey。
一般木马进来之后,除了目的性的攻击(例如虚拟钱包转账、文件加密勒索)外,它还会使劲去找各种敏感信息,尤其是浏览器里的登录态、Keychain 里保存的账号密码、聊天工具的登录状态、开发环境里的 .env 文件和各种 token,等等。
我这个教训,大家记住两点:1)所有能够加 F2A 的账号都要加,登录时的二次验证会增加攻击者的门槛;2)AI 在执行各种程序的时候,一定要注意它在执行什么,尤其是安装和更新软件的时候,要先确认再执行。
跟一些安全研究者也交流了这个木马的细节,他说近期这类事件特别高频,攻击者会伪造各种软件的官网,Google 搜出来默认都排在第一位,诱导用户(尤其是 AI)下载木马,防不胜防!
@Barret_China
这个账号在过去一段时间,一直处于不可用状态,被黑客添加了 passkey 之后,给我改了密码,改了邮箱,改了手机号码。完全被接管。 我这个账号开启了 F2A,能加的安全措施也都加了,挺好奇是如何绕过的。 这几天让 Claude 给我电脑做了深度体检,对启动的每个进程都做了分析,排查到,有一个伪装得特别好的木马,在我电脑跑了快一个月! 申诉了好几天,也找了不少朋友帮忙,还是把账号搞回来了。后面再详细分享下过程。 另外,也注册了一个防丢的小号,可以加个关注,@barretlee_china 😄
大概一个多月前,我的电脑中了木马,潜伏了一个月才被发现,也导致了我的 X 账号被盗。 用 Claude 和 Codex 逐一分析系统进程时,发现了一个叫 com.apple.accountsd.helper.plist 的进程,乍一看以为是苹果系统进程,但 Claude 对其提出了质疑。 顺着这条线索深入分析:木马先添加开机自启项长期潜伏,再用 root 权限写守护脚本,每秒探测是否有新用户登录,一旦登录就通过 AppleScript 切换为当前用户身份,运行一个叫 AccountsHelper 的程序。 对 AccountsHelper 做二进制分析,发现它依赖极少,主要职责是从远端加载指令,然后拉起一个交互式 PTY shell,攻击者就是通过这个 shell 远程操控电脑的。木马的每个环节清理工作都做得极好,几乎所有日志都被清除。 为溯源整个入侵过程,我分析了近两个多月的系统日志,只找到一条可疑指令:一个 curl 操作,下载并执行了一段混淆命令,这是唯一线索,解密后得到一个远端 IP 地址。 从公开情报中找到了这个木马,它是 AMOS Stealer 恶意软件家族的变种,之前主要针对 Windows,今年四月首次在 macOS 上被发现。 从 .zhistory 日志看,curl 前后都是 Claude Code 相关操作,高度怀疑是 agent 程序引入了这个木马。 我的 Claude Code 长期处于 bypass 模式,所有命令直接放行,怀疑是在安装或更新软件时,AI 从互联网找到了不安全的资源并下载了木马。 AMOS 木马主要扫描各类虚拟货币钱包(尤其是浏览器插件钱包),同时也把我的各种登录 Cookie 全部窃取,这才导致 X 账号被恶意添加了 Passkey。 木马入侵后,除了针对性攻击(如虚拟钱包转账、文件加密勒索)外,还会大肆搜集敏感信息:浏览器登录态、Keychain 账号密码、聊天工具登录状态、开发环境的 .env 文件和各类 token 等。 两个教训:1)所有能开 2FA 的账号都要开,登录时的二次验证能有效提高攻击门槛;2)AI 执行各种程序时务必注意它在做什么,尤其是安装和更新软件时,要先确认再执行。 和安全研究者交流后得知,近期此类事件极高频——攻击者会伪造各类软件官网,Google 搜出来默认排在第一位,专门诱导用户(尤其是 AI)下载木马,防不胜防!
@dair_ai·6月19日
RT @omarsar0: // Automating SKILL.md Generation //
Increasingly, mining sessions is one of the best ways to improve your agents.
OpenAI r…
// 自动化生成 SKILL.md // 越来越多人发现,挖掘历史 session 是改进 agent 的最佳途径之一。 OpenAI r…
@mattpocockuk·6月19日
Yesterday, I shipped v1 of mattpocock/skills, including:
- /ask-matt: ask me how best to use the skills, from right in your agent
- Model-invoked vs User-invoked skills
- /writing-great-skills, which encodes my skill-writing best practices
Enjoy: https://t.co/7PcrO9rfS3

昨天发布了 mattpocock/skills v1,包含: - /ask-matt:在 agent 内直接问我如何最好地使用这些 skills - Model-invoked 与 User-invoked skills 的区分 - /writing-great-skills:编码了我的 skill 编写最佳实践 欢迎使用。
@dair_ai·6月19日
Generate Artifacts from YouTube videos with our new /youtube-notetaker skill.
@omarsar0
YT Videos -> Aritfacts Watch how I use my new /youtube-notetaker skill to generate artifacts from YT videos. Captures slides, notes, transcriptions,... Go try it ↓ https://t.co/BxGwMNyGE4
用我们新的 /youtube-notetaker skill 从 YouTube 视频生成 Artifacts。 [引用 @omarsar0]: YT 视频 -> Artifacts 看我如何用新的 /youtube-notetaker skill 从 YT 视频生成 artifacts。可以提取幻灯片、笔记、字幕... 快去试试 ↓
@mattpocockuk·6月19日
Folks who are running GLM 5.2, how are you doing it?
What harness/provider are you using?
Getting FOMO about an open weights model for the first time
正在跑 GLM 5.2 的朋友们,你们是怎么做的? 用的什么 harness/provider? 这是我第一次对一个开源权重模型产生 FOMO
@wengtianxin·6月19日For You
Vibe coding 现状:功能开发 7 分钟,古法手工打磨 UI 和动效 7 小时🤪
Vibe coding 现状:功能开发 7 分钟,古法手工打磨 UI 和动效 7 小时🤪
@HiTw93·6月19日For You
挺有趣,听朋友说我这几篇文章成为了现在 AI 岗位面试准备必读的文章,那我来汇总一下给大伙好啦,希望有帮助,当然也祝福最近从传统岗位工程师转型成 AI 岗位的小伙伴找到自己满意的工作。
1. 你不知道的 Claude Code:架构、治理与工程实践
https://t.co/p0RWjHcklI
2. 你不知道的 Agent:原理、架构与工程实践
https://t.co/4FXcGYqbaJ
3. 你不知道的大模型训练:原理、路径与新实践
https://t.co/DJuvPaBvhu
4. 你不知道的 AI Coding:非技术人的上手、场景与实战
https://t.co/TLi4q9XOtJ
5. 你不知道的 GEO:AI 可见性的原理、实践与取舍
https://t.co/VrLUqgucwR
6. 你不知道的具身智能:从小机器狗到 Optimus
https://t.co/bRBbRZXIZg
@HiTw93
你不知道的 Claude Code:架构、治理与工程实践
听朋友说这几篇文章成了 AI 岗位面试备考必读,汇总一下,希望对大家有帮助,也祝正在从传统工程师转型 AI 岗位的朋友顺利找到满意的工作。 1. 你不知道的 Claude Code:架构、治理与工程实践 2. 你不知道的 Agent:原理、架构与工程实践 3. 你不知道的大模型训练:原理、路径与新实践 4. 你不知道的 AI Coding:非技术人的上手、场景与实战 5. 你不知道的 GEO:AI 可见性的原理、实践与取舍 6. 你不知道的具身智能:从小机器狗到 Optimus
@9hills·6月19日For You
herdr 很不错,但是一直想要一个基于 Session 管理的。最近发现了 agent-deck,用了用,感觉不错。
以 session 为管理核心,包括session resume/fork 等等。体验很好。 https://t.co/Sf1034bPWn

herdr 挺不错,但我一直想要一个以 session 为核心来管理的工具。最近发现了 agent-deck,用了用感觉不错。 以 session 为管理核心,支持 session resume/fork 等功能,体验很好。
@simonw·6月19日
Really looking forward to one of the super-fast custom silicon inference providers like @GroqInc or @cerebras getting GLM 5.2 running
Cerebras has GLM-4.7, Groq is still mostly Llama 3.x and gpt-oss
@jeremyphoward
Wow. @Zai_org GLM 5.2 is a marvel! It is *at least* as good as Opus 4.8 and GPT 5.5. It's super fast, inexpensive, and not too verbose. It responds with nuance and judgement, & handles long context VERY well. I've never experienced an open weights model like this before.
非常期待 @GroqInc 或 @cerebras 这类超快定制硅推理服务商能跑起 GLM 5.2。 Cerebras 已有 GLM-4.7,Groq 目前主要还是 Llama 3.x 和 gpt-oss。 【引用 @jeremyphoward】: 哇。 GLM 5.2 简直是奇迹!它**至少**和 Opus 4.8、GPT 5.5 一样强。速度超快、价格低廉、回复不啰嗦。 它的回答有细微判断力,长上下文处理也非常出色。 我从没见过这样的开源权重模型。
@FardeemM·6月19日For You
If you're on your way to building a billion dollar company that involves a web app, here are some of my notes on architecting the frontend.
if you don't do this, it's probably fine but one day you'll hire someone to fix it but truly that person could be doing some other higher value thing if you make some key optimizations on day 1
you don't even have to learn anything you're gonna tell your agents to do it anyways!
okay here it goes:
- Make your server code generate a openapi spec which then generates all the relevant client side code. Never do this by hand. Typing backend types instead of generating them should be banned
- You need to make a decision on how the client talks to the backend. rest/graphql works in which case please just use tanstack query. other libraries will look similar but tanstack query truly is goated.
- if you want linear style sync setups or offline mode, think about this HARD and architect it from day 1. Bolting this on later is so tedious.
- People like using plain react router but things have gotten a lot better since then. Try their new framework mode or just even use tanstack router. Use route data loaders.
- If you store a lot of state in query params, make that a first class citizen and make sure its type safe. use nuqs or tanstack query.
- Most apps just need a single state management situation for server state and thats it. If you have other bespoke needs, i have quite like zustand and xstate/store.
- If you have a super interactive app where things come in and out of view, theres a lot of frontend state to maintain, music is playing and what not, lock in and learn xstate. Trust me if you wanna keep ur sanity, you need to model ur frontend as a state machine otherwise you're gonna be deep in useEffect hell
- React compiler is here my friends, the days of useMemo and useCallback are gone. Update your priors accordingly
- Tailwind is easy and fun but makes it really hard to maintain a large app with consistent styling. You need a "agent-first design system/component library" but maybe this is a rant for another day
- Don't be afraid to hack your routing library to fit your needs more closely. A lot of apps have "drawers" to show additional info. You should 100% be able to say "here's a route, make it a drawer" and everything should be handled from there.
- Managing loading and error states using isPending and isError is madness. Lean into Suspense and ErrorBoundary.
- Figuring out a blessed path for websockets and SSE on day 1 i think will pay dividends in the long term if you're building anything AI related.
- If you're building a SPA, don't use next.js. it literally makes no sense. Why would you do this.
- Definitely deploy on Cloudflare or vercel. There are other services but trust, there have weird missing features.
- Assuming you build something people want, the next job is to build the factory so it can efficiently build the thing. Act accordingly.
如果你正在做一个涉及 web app 的十亿美元公司,这里是我关于前端架构的笔记。 不做这些大概率也没事,但迟早会雇人来修——而那个人本可以做更有价值的事,如果你在第 1 天就做对几个关键决策的话。 而且你甚至不用自己学,直接让 agent 来做就行! 好,开始: - **让 server 代码生成 OpenAPI spec,再从 spec 生成所有客户端代码。永远不要手动写。**手敲 backend 类型而不是生成,应该被禁止。 - 你需要决定客户端如何与 backend 通信。REST/GraphQL 都行,这种情况下请用 TanStack Query。其他库看起来类似,但 TanStack Query 真的是神。 - 如果想要 Linear 那种实时同步或离线模式,**从第 1 天就认真想清楚并把架构定好**。事后加上去极其痛苦。 - 很多人喜欢用纯 React Router,但现在已经进化很多了。试试它的 framework 模式,或者直接用 TanStack Router。用 route data loaders。 - 如果大量状态存在 query params 里,把它做成一等公民并确保类型安全。用 nuqs 或 TanStack Query。 - 大多数 app 只需要一套管理 server state 的状态管理方案就够了。如果有其他特殊需求,我比较喜欢 zustand 和 xstate/store。 - 如果你的 app 高度交互、内容频繁进出视图、还在放音乐之类的,**认真学 xstate**。如果想保住理智,你需要把前端建模成状态机,否则你会深陷 useEffect 地狱。 - React compiler 来了,useMemo 和 useCallback 的时代结束了。更新你的认知。 - Tailwind 简单好玩,但在大型 app 里很难维持一致的样式。你需要一个「agent-first 设计系统/组件库」,但这是另一个话题了。 - 不要怕魔改你的路由库来更贴合你的需求。很多 app 有 drawer 来展示额外信息。你应该能说「这是一个 route,把它做成 drawer」,剩下的全自动处理。 - 用 isPending 和 isError 管理 loading 和 error 状态是一种折磨。多用 Suspense 和 ErrorBoundary。 - 如果你在做 AI 相关的东西,第 1 天就定好 WebSocket 和 SSE 的标准方案,长期来看绝对值得。 - **如果你在做 SPA,别用 Next.js**,真的毫无意义。 - 部署在 Cloudflare 或 Vercel。其他服务总有奇怪的功能缺失。 - 假设你做出了人们想要的东西,下一个任务是**把工厂建好,让它能高效地持续生产**。按这个逻辑行动。
@dani_avila7·6月19日For You
New Claude Code (v2.1.181) has a small but useful DX improvement
You can now set any session setting inline with /config key=value, without opening the menu:
/config useAutoModeDuringPlan=false
Works in interactive, -p, and Remote Control
Would like the same pattern for /model, /effort, /color, and even skill arguments 👀

新版 Claude Code (v2.1.181) 有个小而实用的 DX 改进: 现在可以用 /config key=value 内联设置任意 session 参数,不用再打开菜单: /config useAutoModeDuringPlan=false 在 interactive、-p 和 Remote Control 模式下都有效。 希望 /model、/effort、/color 甚至 skill 参数也能用同样的模式 👀
@simonw·6月19日
Just launched Datasette Apps - a plugin for Datasette that lets you host full HTML+JS apps in an iframe sandbox that can query your database and do interesting things with your data
https://t.co/j9VGMhTRZc
刚发布了 Datasette Apps——一个 Datasette 插件,可以在 iframe 沙箱中托管完整的 HTML+JS 应用,这些应用能查询你的数据库并对数据做各种有意思的处理。
@jonas_nelle·6月18日For You
Automating your repetitive work has never been easier - just run /automate in Cursor
@cursor_ai
Introducing /automate, a skill for agents to set up automations for you. Describe your task in plain language. Cursor configures the triggers, instructions, and tools. https://t.co/PB7kZh0Izt
自动化重复性工作从未如此简单——只需在 Cursor 中运行 /automate [引用 @cursor_ai]:推出 /automate,一个让 agent 帮你配置自动化的 skill。用自然语言描述你的任务,Cursor 自动配置触发器、指令和工具。
@MatthewBerman·6月18日For You
One of my new favorite loops from Peter Steinberger (@steipete):
“Refactor until you are happy with the architecture. After each significant step, live-test the system, run autoreview, and commit. Track progress in /tmp/refactor-{projectname}.md.”
https://t.co/Ipm6CdHAFW
@MatthewBerman
Just launched Loop Library - a curated list of agent loops you can use right now. Find loops, submit your own, tokenmaxx!! https://t.co/7bVzOyZMrt
我最近最喜欢的 agent loop 之一,来自 Peter Steinberger: 「重构直到你对架构满意为止。每完成一个关键步骤后,对系统做实时测试、跑 autoreview、然后提交。在 /tmp/refactor-{projectname}.md 里追踪进度。」
@lennysan·6月18日For You
Having Codex handle all the Google Cloud settings itself (using its in-app browser) is so awesome https://t.co/goLAn1aIo2

让 Codex 用它内置的浏览器自己处理所有 Google Cloud 设置,实在太爽了 https://t.co/goLAn1aIo2
@adocomplete·6月18日
New on the Claude Community page: share what you've built with Claude and get featured.
Also learn about upcoming events, the ambassador program, and more! https://t.co/pQhyX338KC

Claude 社区页面新上线:分享你用 Claude 构建的作品并获得推荐展示,还可了解即将举办的活动、大使计划等。
@mattpocockuk·6月18日
My latest favourite stack is GitHub Actions + Sandcastle + Claude Code
Label an issue, get an implementation
Also works for multi-step PRD's, here's one working live:
https://t.co/yXefmI1IM6
最近最喜欢的 stack:GitHub Actions + Sandcastle + Claude Code 给 issue 打上标签,自动获得实现。 也支持多步骤 PRD,这是一个正在运行的示例:
@bcherny·6月18日
I've been using Artifacts in Claude Code for everything: visual explanations of tricky code, system diagrams, quick previews of a few animation options, data analyses and dashboards I share with the team. They are a game changer for how I work with Claude. Can't wait to hear what you think!
@claudeai
New in Claude Code: Artifacts. Interactive pages built from your session, like a PR walkthrough or a living project dashboard, shared with your team at a private link. Available in beta on Team and Enterprise plans. https://t.co/0NX9gNCaAs
我一直在 Claude Code 中把 Artifacts 用于所有事情:难懂代码的可视化解释、系统架构图、几种动画方案的快速预览、与团队共享的数据分析看板。它彻底改变了我与 Claude 的协作方式。迫不及待想听大家的使用感受! 【引用】Claude Code 新功能:Artifacts。 从你的会话中生成交互式页面,比如 PR 演示或实时项目看板,通过私密链接与团队共享。 Team 和 Enterprise 计划现已开放 Beta 测试。
@dotey·6月18日For You
OpenAI Codex 上线了 Record & Replay 功能:在 Mac 上把一个重复性操作演示一遍,Codex 会观察你的操作过程,自动生成一个可复用的 Skill。下次遇到同样的任务,换一组输入参数,Codex 就能替你重新执行。
目前仅限 macOS,欧盟地区暂不可用,使用前需要先开启 Computer Use。
这个功能解决的问题很具体。很多日常工作流程步骤固定但难以用文字描述清楚:报销填单要选对科目和审批人,发布视频要按固定顺序填标题、标签、缩略图,创建 issue 要勾选特定的标签和指派人。以前想让 AI 帮你做这些事,你得把每一步写成精确的指令。Record & Replay 的思路是,与其写说明书,不如做一遍给它看。
操作流程不复杂。在 Codex 桌面端打开 Plugins,点加号菜单,选 Record a skill,然后正常在 Mac 上完成一遍操作。完成后停止录制,Codex 会分析你的操作,生成一份 Skill 文件,里面包含触发条件、所需输入、执行步骤和验证方式。这份 Skill 可以检查、可以编辑,不是黑盒。
重放的时候,开一个新对话,告诉 Codex 用这个 Skill,给它这次不同的参数就行。Codex 会结合 Computer Use(桌面操控)、浏览器操作和已连接的 plugin 来完成任务。
@OpenAIDevs
Show Codex a workflow once. Reuse it as a skill. Record & Replay lets you show Codex a recurring task, like filing an expense report or submitting a time-off request. Codex turns that demo into an inspectable, editable skill. You control when recording starts and stops. https://t.co/UqSGaO7XUs
OpenAI Codex 上线了 Record & Replay 功能:在 Mac 上把一个重复性操作演示一遍,Codex 会观察你的操作过程,自动生成一个可复用的 Skill。下次遇到同样的任务,换一组输入参数,Codex 就能替你重新执行。 目前仅限 macOS,欧盟暂不可用,需先开启 Computer Use。 这个功能解决的问题很具体。很多日常工作流程步骤固定但难以用文字描述清楚:报销填单要选对科目和审批人,发视频要按固定顺序填标题/标签/缩略图,创建 issue 要勾选特定标签和指派人。以前想让 AI 做这些,你得把每一步写成精确指令。Record & Replay 的思路是——与其写说明书,不如做一遍给它看。 操作流程不复杂:在 Codex 桌面端打开 Plugins,点加号菜单,选 Record a skill,然后正常在 Mac 上完成一遍操作。完成后停止录制,Codex 会分析操作,生成一份 Skill 文件,包含触发条件、所需输入、执行步骤和验证方式。这份 Skill 可以检查、可以编辑,不是黑盒。 重放时开一个新对话,告诉 Codex 用这个 Skill,给它不同的参数就行。Codex 会结合 Computer Use(桌面操控)、浏览器操作和已连接的 plugin 来完成任务。
@mattpocockuk·6月18日
RT @DavidOndrej1: Matt Pocock just explained why everyone is obsessing over the wrong thing
it's not the model, it's the harness
watch th…
Matt Pocock 刚刚解释了为什么大家都在关注错误的东西—— 不是模型,是 harness(编排层)
@trq212·6月18日
Claude Code can now upload and edit HTML artifacts that you can share with your team or other Claudes!
Starting with teams so you can share internally with your team, coming to Pro and MAX plans soon!
@claudeai
New in Claude Code: Artifacts. Interactive pages built from your session, like a PR walkthrough or a living project dashboard, shared with your team at a private link. Available in beta on Team and Enterprise plans. https://t.co/0NX9gNCaAs
Claude Code 现在可以上传和编辑 HTML artifacts,可以分享给团队或其他 Claude! 先向 Teams 计划开放,Pro 和 MAX 计划即将跟进。 (引用 @claudeai)Claude Code 新功能:Artifacts。 从你的会话直接生成交互页面——比如 PR 解读或实时项目看板,通过私有链接分享给团队。 现已在 Team 和 Enterprise 计划 Beta 上线。
@0xblacklight·6月18日For You
lots of folks have been talking about loops lately
most loops suck
here's a practical one we actually use
agents suck at writing react
react-doctor by @aidenybai is our favorite way to deal with this
you could run it and use a ralph loop to fix everything
but I'm not reading a +80k/-80k PR (and neither is @dexhorthy)
But I can read a small one first thing every morning when i get into the office
here's what we do:
run react-doctor in CI once daily at 7am (github actions-as-a-sandbox btw)
agent picks top 5 issues, fixes them, and opens a PR
other CI jobs check for regressions on every PR
we can't realistically fix everything at once
but we can keep it from getting worse
and make it 1% better every day

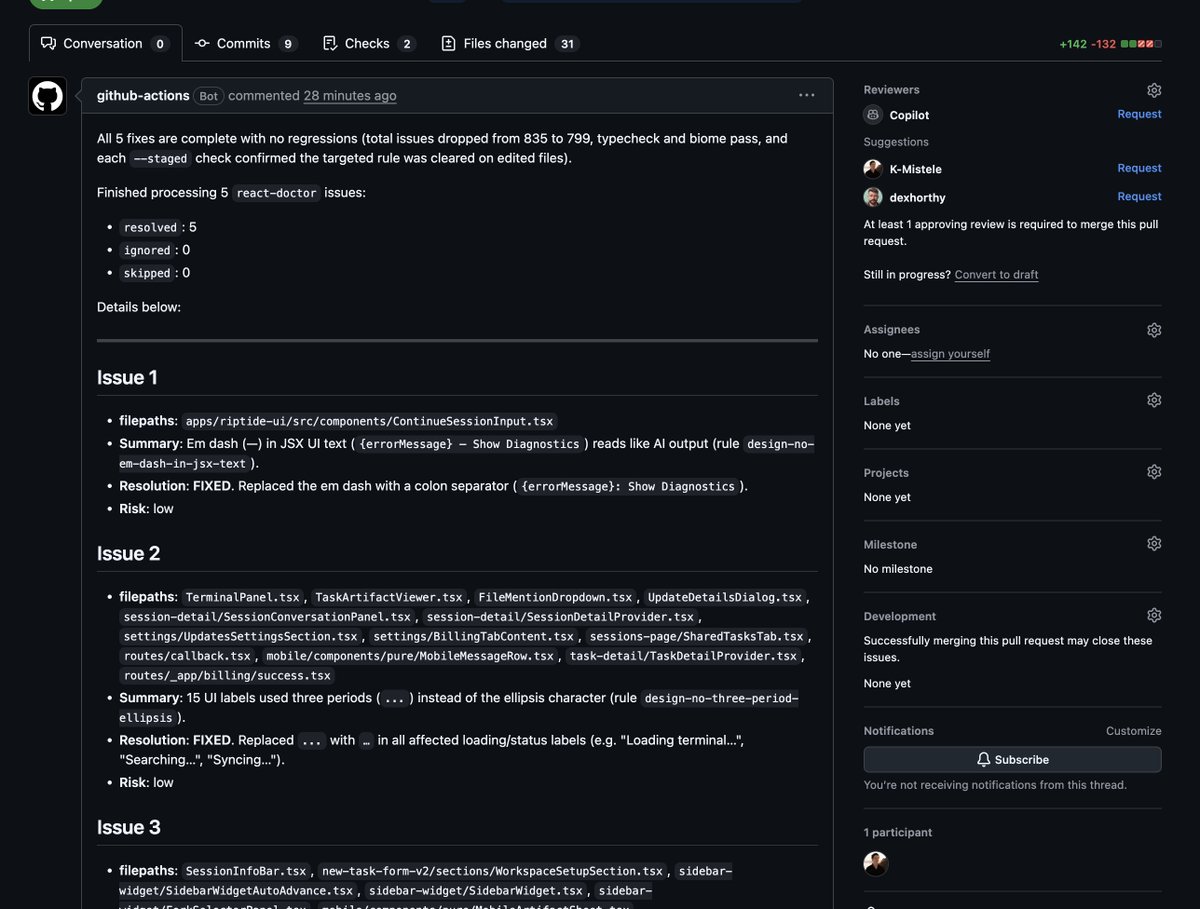
最近大家都在聊 loop,但大多数 loop 方案都烂透了。 分享一个我们实际在用的: Agent 写 React 代码很烂。@aidenybai 的 react-doctor 是我们对付这个问题的最爱。 你可以跑一次、用 ralph loop 把所有问题修光——但我不会去 review 一个 +80k/-80k 的 PR(@dexhorthy 也不会)。 但我每天早上到办公室后能读一个小 PR。 我们的做法是: 每天早上 7 点在 CI 里跑 react-doctor(顺带说,GitHub Actions 是个绝佳沙盒) Agent 挑出前 5 个问题,修完,开一个 PR 其他 CI job 在每个 PR 上检查回归 没办法一次把所有问题修完,但可以做到两件事:不让它变得更坏,以及每天 1% 的改进。
@kunchenguid·6月18日For You
time to reveal the next big gun in my agentic engineering setup - Firstmate!
it's the only agent session i directly talk to now. if you find it mentally exhausting to juggle between all the agent sessions, this is the solution
free & open source as always - details below 👇 https://t.co/UEvPoPv3iK

揭晓我 agentic engineering 工作台的下一件重器——Firstmate! 这是我现在唯一直接对话的 agent session。如果你觉得同时管理多个 agent session 很耗费心力,这就是解法。 一如既往免费开源——详情见下 👇
@zeeg·6月18日For You
I'd love to see examples of a great eval setup that runs against a complex agent.
We all know that asserting input prompt to output prompt isnt testing anything, but I'm curious how everyone actually checks behavior.
Things like: did the agent make this tool call? did it hit this network endpoint? did it write to this data store?
Obviously some of those are determnistic, but some come from actual behavior within the loop.
我很想看到针对复杂 agent 的优秀 eval 设置案例。 大家都知道,断言「输入 prompt → 输出 prompt」根本没在测任何东西,但我很好奇大家实际上是怎么检验行为的。 比如:agent 有没有发出这个 tool call?有没有命中这个网络端点?有没有写入这个数据存储? 其中有些是确定性的,但有些源自 loop 内部的真实行为。
@nifinet·6月18日For You
How to Build a GTM Team on Claude Code You Can Run Alone
如何用 Claude Code 搭建一个你一个人就能运营的 GTM 团队
@JasonZX·6月18日For You
我草。用GLM-5.2(左侧)和Opus 4.8(右侧)做一个登录页面,效果请对比。另外Token的成本是GLM 0.06美元,而Opus成本0.49美元。 https://t.co/C2ozJsmKkT

我草。用 GLM-5.2(左)和 Opus 4.8(右)各做一个登录页面,效果请自行对比。另外 token 成本:GLM 0.06 美元,Opus 0.49 美元。
@dair_ai·6月18日
RT @omarsar0: Cool paper on Skill routing for LLM agents.
Real tasks rarely map to a single skill. They need several composed together, bu…
关于 LLM agent 技能路由的新论文。真实任务很少能映射到单一技能,往往需要多个技能组合——但如何优雅地路由和组合,是个难题。
@dair_ai·6月18日
If you build web agents, this one is worth your time.
It's on how to make agent skills reusable.
(bookmark it)
LLM web agents usually run as tool callers. Each turn, the model reads a fresh page and emits one low-level action, so horizons and policy-facing LLM completions both blow up on benchmarks like Mind2Web and WebArena.
Skill libraries are meant to fix this by wrapping repeated fragments as callable tools, but they trigger reuse on instruction similarity or site metadata, which barely fires on held-out sites.
This work routes skill reuse by transferable interaction patterns instead, so a skill learned on one site fires on new sites that share the same interaction shape. That lifts reuse where domain-keyed retrieval falls flat.
Why does it matter?
The same search, filter, and paginate dance shows up across sites. Abstracting it into a pattern-keyed skill makes web-agent skills generalize beyond the site on which they were learned.
Paper: https://t.co/ku7kFIBhhy
Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c

做 web agent 的值得看这篇。 讲的是如何让 agent skill 可复用。 (收藏) LLM web agent 通常作为 tool caller 运行。每轮模型读取新页面并执行一个低层动作,导致在 Mind2Web、WebArena 等 benchmark 上 horizon 和策略侧 LLM 补全双双崩溃。 Skill library 本来是为了解决这个问题——把重复片段封装成可调用工具。但传统方案按指令相似度或站点元数据来触发复用,在 held-out 站点上几乎不生效。 这项工作改用「可迁移交互模式」来路由 skill 复用,让在某个站点学到的 skill 能在具有相同交互形态的新站点上触发。这在基于域名的检索失效的场景下显著提升了复用率。 为什么重要? 搜索、筛选、翻页这套流程在各个网站上反复出现。把它抽象成模式键控的 skill,就能让 web agent skill 泛化到训练站点之外。
@dair_ai·6月18日
RT @dair_ai: Who should design the training environment for an RL agent, the practitioner or the policy itself?
RL pipelines for LLMs usua…
谁应该设计 RL agent 的训练环境——从业者,还是 policy 本身? LLM 的 RL pipeline 通常……
@mattpocockuk·6月18日
Playing around with the idea of decision maps
1. Figure out the 'frontier' of decisions with a short grilling session
2. Fan out to multiple grilling/prototyping/research sessions, uncovering the fog of war as you go
Here I go, grilling on three aspects of a huge build: https://t.co/KRy6tqILwA

在玩一个「决策地图」的想法: 1. 通过简短的追问环节找出决策的「边界层」 2. 展开多个并行的追问/原型/研究 session,逐步驱散迷雾 实录:同时对一个大项目的三个方面展开追问:
@mattpocockuk·6月18日
Let me put this more simply:
Skills need to be able to import other skills without imposing a token cost
@mattpocockuk
A frustrating gap I'm hitting in the skills spec. TL;DR: I want three tiers of 'invocable'. User-invocable, skill-invocable, and model-invocable. Skill-invocable skills are only invocable by the user, or by skills. Skills can be marked as model-invocable or user-invocable. Model-invocable skills put their description into context. User-invocable skills are hidden from the model, so no tokens are burned on the description. But what about skills that you want to BOTH invoke on their own (user-invocable only), but also use as parts of other skills? An example would be a /review skill, which: 1. Runs some automated checks on the repo 2. Checks the code against the original spec 3. Checks it against some coding standards What if you want to pull out step 1 into its own skill? /run-automated-checks You'd create that skill, then reference it in the /review skill: "1. /run-automated-checks" In order to move that into its own skill, you MUST make it model-invocable - meaning its description goes into context. This is pointless token waste. You can't omit the description - that goes against spec. But you'd just write a description saying "never invoke this except in other skills". Anyone working on the skills spec? Has this been considered?
简单说就是: Skill 必须能引用其他 skill,且不产生额外的 token 开销。 【引用原文】 Skills spec 里我碰到了一个让人抓狂的 gap。 TL;DR:我想要三种「可调用」层级——用户可调用、skill 可调用、model 可调用。Skill 可调用的 skill 只能被用户或其他 skill 触发。 Skill 可以标记为 model-invocable 或 user-invocable。Model-invocable 的 description 会注入 context;user-invocable 对 model 不可见,不消耗 token。 但问题来了:如果一个 skill 既想独立使用(user-invocable),又想作为其他 skill 的子步骤,该怎么办? 比如 /review skill: 1. 跑自动化检查 2. 对照原始 spec 审查代码 3. 对照编码规范审查 如果把第 1 步拆成独立的 /run-automated-checks,你就必须把它设为 model-invocable——description 就进了 context。 这是无意义的 token 浪费。你不能省略 description(违反 spec),又只能写一句「除非在其他 skill 里调用,否则永远不要触发」。 有人在做 skills spec 吗?这个问题考虑过吗?
@realWeZZard·6月18日For You
我今天使用 codex 改了前 AI 时代的一个 project。很惊讶的是,现在已经不需要再预先初始化 AGENTS.md 或者 CLAUDE.md 了。Context Engineering 本身已经被模型内化了。
我今天用 codex 改了一个前 AI 时代的老项目。令我惊讶的是,现在已经不需要预先初始化 AGENTS.md 或 CLAUDE.md 了。Context Engineering 本身已经被模型内化了。
@bcherny·6月18日
RT @claudeai: New in Claude Design: it stays on brand with your design system across projects, lets you edit directly on the canvas, syncs…
Claude Design 新功能:跨项目保持设计系统品牌一致性,支持直接在 canvas 上编辑,并可同步……
@dair_ai·6月18日
Who should design the training environment for an RL agent, the practitioner or the policy itself?
RL pipelines for LLMs usually rely on manually redesigned environments between stages, with practitioners guessing which configuration will best improve the current policy.
This work proposes an LLM-as-Environment-Engineer framework. The current policy analyzes its own failure trajectories plus context and proposes the next-stage environment configuration, automating a step that has stayed stubbornly manual. They also release MAPF-FrozenLake, a controllable multi-agent testbed whose generator exposes multi-dimensional environment configs.
Why does it matter?
Curriculum design between RL stages is mostly gut feel today. Letting the policy read its failures and shape the next environment closes a loop that practitioners currently close by hand.
Paper: https://t.co/lZHlqozrQD
Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c

谁应该设计 RL agent 的训练环境——实践者还是策略本身? LLM 的 RL pipeline 通常依赖实践者在各阶段之间手动重新设计环境,靠猜测哪种配置能最好地改善当前策略。 这项工作提出了 LLM-as-Environment-Engineer 框架。当前策略分析自身的失败轨迹及上下文,并提出下一阶段的环境配置,将这个长期依赖人工的步骤自动化。他们还发布了 MAPF-FrozenLake,一个可控的多 agent 测试床,其生成器支持多维度环境配置。 为何重要? RL 阶段间的课程设计如今主要靠直觉。让策略读取自身失败并塑造下一个环境,补上了实践者当前手动完成的这个闭环。
@zarazhangrui·6月18日For You
Don't use AI for writing until you develop your own taste and voice
Using AI to write isn't inherently bad. The danger is using AI to write before you've developed your taste for what is good content. If the AI produces slop, you won't even recognize it as slop
Read a lot to figure out what good looks like. Write a lot to know what your voice sounds like. Only then, use AI to help you write, but make sure it actually sounds like you
在你形成自己的品味和声音之前,不要用 AI 写作。 用 AI 写作本身没有错。危险在于,你还没建立起对「好内容」的判断力就开始用 AI 写。如果 AI 产出的是烂货,你甚至认不出来它是烂货。 多读,弄清什么是好的。多写,认清自己的声音是什么。只有在那之后,才用 AI 辅助写作——并确保输出读起来真的像你。
@petergyang·6月17日For You
So I have Codex running on a /goal and it's been working for 2 hours but the problem is it's making alot of wrong assumptions so I have to monitor and steer it constantly.
Is this expected? Perhaps I should've had it make a detailed plan first?
所以我让 Codex 跑了一个 /goal 任务,已经跑了 2 小时,但问题是它做了很多错误假设,我必须一直盯着它、不断纠偏。 这正常吗?也许我应该先让它做一个详细的计划?
@ClaudeDevs·6月17日For You
Claude Code and Claude Design now sync both ways.
Run /design-sync to pull your design system into your repo and build against your real components, or push what you've built back into Claude Design and keep editing on the canvas.
@claudeai
New in Claude Design: it stays on brand with your design system across projects, lets you edit directly on the canvas, syncs with Claude Code, and connects to more of the tools you already use. https://t.co/MK8YvLP8zV
Claude Code 与 Claude Design 现已实现双向同步。 运行 /design-sync 可将你的设计系统拉取到仓库,直接基于真实组件进行开发;或将你已构建的内容推送回 Claude Design,继续在画布上编辑。 [引用 @claudeai]: Claude Design 新功能:跨项目保持品牌一致性、支持直接在画布上编辑、与 Claude Code 同步,并接入更多你已在用的工具。
@dair_ai·6月17日
Outstanding paper on computer-using agents.
(bookmark it)
Computer-using agents drive real software through the screen, but they solve every task from scratch. Ask one to repeat a task, and it re-reads the screen and re-reasons every tap, paying the full cost again.
PreAct compiles the first successful run into a small state-machine program, states that check the screen and transitions that act, then replays it directly on later runs. That runs 8.5 to 13x faster with no per-step language-model calls.
Replay stays guarded. At each step, PreAct checks that the screen matches what the program expects before acting, and hands control back to the agent when reality diverges.
Why does it matter?
Most computer-use costs are repeated reasoning on tasks the agent has already solved. Amortizing that into a replayable program is a clean way to make agents faster the second time.
Paper: https://t.co/kMloX0qC5M
Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c

关于计算机操控 agent 的优秀论文。(值得收藏) 计算机操控 agent 通过屏幕驱动真实软件,但每次任务都从头解决。让它重复同一个任务,它会重新读屏幕、重新推理每一次点击,全部成本再付一遍。 PreAct 将首次成功运行编译成一个小型状态机程序——状态负责检查屏幕,转换负责执行动作——并在后续运行中直接回放。速度提升 8.5 到 13 倍,无需每步调用语言模型。 回放有保护机制。每一步,PreAct 都会验证屏幕是否与程序预期匹配再执行动作;若现实偏离,则将控制权交还给 agent。 为何重要? 计算机操控的大部分成本在于对已解决任务的重复推理。将其摊销为可回放程序,是让 agent 第二次运行时变快的简洁方案。
@servasyy_ai·6月17日For You
Agent Loop 很火,但基座才是关键:从单代理到自我进化系统的 14 步路线图
Agent Loop 很火,但基座才是关键:从单代理到自我进化系统的 14 步路线图
@servasyy_ai·6月17日For You
Cursor 刚刚举办了他们的首次大会。
他们发布了:
- 从零训练的 1.5T 参数模型
- GitHub 的直接替代品 Origin
- iOS 应用
没人预料到这一幕 👇
https://t.co/7z0oz1zox8

Cursor 刚刚举办了他们的首次大会。 发布了: - 从零训练的 1.5T 参数模型 - GitHub 的直接替代品 Origin - iOS 应用 没人预料到这一幕 👇
@mattpocockuk·6月17日
/teach now creates reusable components which get improved/developed as you learn more
More token-efficient, and builds momentum
Look at these sweet cubes: https://t.co/IpHZs6Zsd9
/teach 现在会创建可复用组件,随着你学习的深入持续改进和演化。 更节省 token,也能积累学习动力。 看看这些漂亮的方块:
@dexhorthy·6月17日For You
look I love rahul and so much of this post is soooo good but i take issue that it opens with "models can basically compile english into correct code"
i did as much work with fable as I possible could and in very few cases did i find the code to be "correct" - sure it worked most of the time, but you could say the same of opus 4.5 -
if we're talking about improvements in correctness I want to see actual well factored code thats not gonna fall apart in 3-6 months - and fable didn't do that. not even close. new abstractions, incorrect patterns, forking shell commands on the server...the whole 9 yards.
the things I really liked:
- optimize for leverage - not everything needs full code review but there will be things that do and you better make sure the core of your app is well-structured, cause the models can't be trusted to do that yet
- quarantining parts of the code for complexity that can be black-boxed and fully verified, treating them like neural nets etc where we only look at the outputs not the internals
- the importance of knowing the whole stack and breaking down problems accordingly
@rahulgs
1. as a mental model it is more correct to think of fable+ class models as english -> code interpreters - converts your idea into code into "correct" code regardless of problem complexity and output complexity (diff size). Fable 5 will be the worst of this new class of models 2. diff size/complexity is to be managed purely for review: small diffs - in high risk areas of code (auth/identity/data access/network access/money movement) large diffs for code that can be empirically verified (frontend/backend plumbing/code without network or db access/performance code that can be empirically verified) 3. time it takes to ship software is completely disconnected from time to produce the PR - how long the work takes depends fully on ability to review/merge code while managing risk at scale 4. solving the bottlenecks for above matter enormously- linters/testing/CI/shadow mode verification/empirical verification 5. agency matters enormously- what are the biggest bottlenecks to speeding up the loop and eliminating them? what are the problems that need solving and when do they need solving? what does it take to the solution to all of them today? 6. deep understanding of the full stack matters enormously- what problems are worth pursuing? is there a higher level of problem abstraction to address first? should I give it the sub-sub task, the sub task, or the task itself. what are the major risks with this PR (order of importance: security holes/correctness holes/performance holes). is there a higher speed way of producing data that allows me to merge this? should this be run in shadow or in a sandbox or a flag. understanding every line of logic may not be needed but understanding and managing risk matters enormously. 7. the cost of complexity itself is changing. it might be now worth "maintaining" 50% more code to get a 5% performance win. getting the right abstractions matter less because larger refactors are less tedious. code quality nits become huge drag. very likely, a much smarter model will be maintaining your code so worth taking on more technical debt now. taking the time to hand architect and rebuild systems comes with an enormous cost of velocity 8. if it quacks like a duck and walks like a duck, it's a duck. For low risk cases, it might be more sane to treat code chunks (services / functions) as a black box, like we do for neural networks: do full empirical verification only: has code produced correct outputs for the last 10,100,1000,10k inputs ? can we quarantine this large piece of code - no outbound access to network / database ? what happens when this code is wrong? do we get hacked/or crash(memory/cpu)/is an inconvenience? is it internal facing or external? what can we do to address these risks? 9. eventually, logical verification (line by line review) will come at an enormous cost- save it for where it matters and build systems that are tolerant to empirical verification. is there a decorator that prevents db / network access? correctness bugs are significantly easier to rectify than access bugs 10. what are the rails that allow for even faster iteration? code permissions can be opt in - db writes, db reads, network egress (to where?), PII access. how long does it take to get shadow mode data? how many PRs can be tested? What are the categories of diffs
说实话我很喜欢 rahul,这篇文章的大部分内容都非常精彩,但我对开篇那句「模型基本上可以把英文编译成正确的代码」有异议。 我尽可能深入地用 Fable 做了测试,几乎没有发现代码是「正确」的——虽然大多数时候能跑起来,但 opus 4.5 也能做到这一点。 如果我们谈的是正确性的提升,我想看到的是真正结构良好、3-6 个月后不会崩掉的代码——而 Fable 远没做到。新的抽象层乱加、pattern 用错、在 server 端 fork shell 命令……所有的坑都踩了。 我真正欣赏的几点: - 优化杠杆——不是所有代码都需要完整 code review,但有些核心部分必须认真看,要确保 app 核心架构是健全的,因为模型现在还不值得信任来做这件事 - 把复杂度高但可以黑盒化的代码模块隔离出来,像对待神经网络一样——只看输出,不看内部实现 - 理解全栈的重要性,以及据此拆解问题的能力 【引用 @rahulgs】: 1. 在心智模型上,更正确的思路是把 Fable+ 这一级别的模型看作 English → code 解释器——无论问题复杂度和输出体量(diff 大小)如何,都能把你的想法转化成「正确」的代码。Fable 5 将是这一新型模型类别中最弱的起点。 2. diff 的大小/复杂度应该纯粹为 review 服务:高风险区域(auth/identity/数据访问/网络/支付)要小 diff;可以实证验证的代码(前端/后端管道/无网络或 DB 访问的代码/性能代码)可以大 diff。 3. 软件交付速度与产出 PR 的速度完全脱钩——真正的耗时取决于在规模化风险管理下 review 和合并代码的能力。 4. 解决上述瓶颈至关重要——linter/测试/CI/shadow mode 验证/实证验证。 5. 主动性(agency)极其重要——什么是提速和消除瓶颈的最大障碍?哪些问题需要解决,何时解决?今天把所有问题一次性解决需要什么条件? 6. 对全栈的深度理解极其重要——哪些问题值得追?是否有更高层次的问题抽象需要先处理?应该给它子子任务、子任务还是任务本身?这个 PR 的主要风险是什么(按优先级:安全漏洞/正确性漏洞/性能漏洞)?有没有更快产出数据从而让这个 PR 可以合并的方式?是该跑 shadow mode、沙箱还是功能开关?不一定需要理解每一行逻辑,但理解和管理风险至关重要。 7. 复杂度本身的成本正在改变。现在可能值得「维护」多 50% 的代码来换取 5% 的性能提升。正确的抽象层变得不那么重要,因为大型重构不再那么繁琐。代码质量上的挑剔反而成了巨大阻力。很可能,更聪明的模型将来会维护你的代码,所以现在背负更多技术债是值得的。花时间手工架构和重建系统的速度代价极高。 8. 如果它走起来像鸭子、叫起来像鸭子,它就是鸭子。低风险场景下,把代码块(服务/函数)当作黑盒可能更明智,就像我们对待神经网络一样:只做完整的实证验证——这段代码在过去 10/100/1000/10000 次输入中产出了正确结果吗?能否把这大块代码隔离——禁止对外网络/数据库访问?代码出错会怎样——被黑/崩溃(内存/CPU)/只是个麻烦?是内部功能还是对外功能?如何规避这些风险? 9. 最终,逐行 review 这种逻辑验证将付出极高代价——省着用在刀刃上,同时构建能够容忍实证验证的系统。有没有 decorator 能防止 DB/网络访问?正确性 bug 比访问控制 bug 容易修得多。 10. 什么样的「护栏」能让迭代更快?代码权限可以按需选择——DB 写、DB 读、网络出口(到哪里?)、PII 访问。获取 shadow mode 数据需要多久?能同时测多少个 PR?diff 的分类有哪些?
@dexhorthy·6月17日For You
the reason matt is spending so much time on great skills for software architecture is the same reason why we're building @humanlayer_dev
https://t.co/gdvZE1hFEM
@mattpocockuk
Announcing mattpocock/skills v1 - Achieved a 63% reduction in token cost for skill descriptions - Split skills into model-invocable and user-invocable skills, adding /codebase-design, /domain-modeling, and /grilling - (UPDATED) /writing-great-skills - rewritten from the ground up, encoding my skill-writing best practices - (UPDATED) /diagnose -> /diagnosing-bugs - now model-invocable, awesome for fixing hard bugs - (NEW) /ask-matt: a router skill that teaches you how all the engineering skills work together
@dexhorthy:matt 花大量时间为软件架构打造优质 skills,背后的原因和我们构建 @humanlayer_dev 是一样的 [引用 @mattpocockuk]:发布 mattpocock/skills v1 - skill 描述的 token 成本降低了 63% - 将 skills 拆分为「模型可调用」和「用户可调用」两类,新增 /codebase-design、/domain-modeling 和 /grilling - (更新)/writing-great-skills——从头重写,融入我的 skill 编写最佳实践 - (更新)/diagnose → /diagnosing-bugs——改为模型可调用,调试复杂 bug 效果很好 - (新增)/ask-matt:一个路由 skill,教你如何把所有工程类 skills 串联起来使用
@francoisfleuret·6月17日For You
Why are Chinese companies releasing very strong open-source models?
为什么中国公司在持续发布非常强的开源模型?
760 tweets · 188 sources