推文
760 tweets · 188 sources账号:全部mattpocockukdair_aisimonwbchernyadocompletetrq212dexhorthyyetonefelixrieseberg0xblacklightdani_avila7zarazhangruiAlchainHustbadlogicgamesdoteypetergyangvikingmuteryancarsonClaudeDevskunchenguidleon7haoctatedeviamzhihuikieranklaassenmckaywrigleylennysanthdxrRhysSullivangarrytanjakevin7johnlindquistkarpathyservasyy_aitheo0xMovez9hillsRLanceMartinaidenybaidingyihylarucodermitchellhmitsuhikomvanhornomarsar0steipetezeegGeminiAppGergelyOroszZaynHaoaddyosmaniantirezdanshipperdillon_mulroyelonmuskewind_devidoubiccnummanalirealWeZZardswyxthsottiauxyiliush0xPaulius0x_rodyAYi_AInotesAnthropicAIBarret_ChinaBenJames_____CMGS1988ChadMoranDanielMiesslerDaveJDavidKPianoDimillianFactoryAIFardeemMFarzaTVGoogleDeepMindHamelHusainHiTw93HilaShmuelIfanJewIndieDevHaileyJack_W_LindseyJackywineJasonZXJiaxi_CuiJinjingLiangKhalidWarsaLinearUncleLinghuaJMatthewBermanMaxForAIMeari_V2_0_GMnilaxQingQ77RaillyHugoSaccc_cTaniyatweets_VincentLogicai_explorer25aibuilderclub_alexalbert__alliekmillerandrewfarahantoinecojpanxue201arkuy99artmanasynkimobbssppllvvbearliubentossellbridgemindaibuaaxhmcailynyongyongcgtwtscharmaine_kleechrisbarberchrisparkXclairevodelba_oliveirademishassabisdoodlesteindriaforallelithrarelvissunericzakariassonfrancoisfleuretgabriell_labiamsahaj_xyzimdigitalashishimvihvjarredsumnerjerryjliu0jianshuojiayuan_jyjlongsterjonas_nellejoshalbrechtjpschroederkaiofreitaskepanolexruslogancyangmattypnabeelnifinetninthbit_aioran_gepatrickcpejmanjohnpetradonkaprathamgrvprathyvshquanruzhuoxiuquant_sheepraroquerealCaigurepsiacerohanpaul_aisamasamuelstroscheisawyerhoodshadcnshao__mengshaogefenhaoshreyansjtechgirl1908techwith_ramthorstenballtianyitobiaswuptoddsaunderstricaltturingoututuretomuniswap12untraceable_thevanillaCitronvelvet_sharkwengtianxinwquguruxiaogaifunxicilionycombinatorzachlloydtweetsziwenxu_zodchiii
@mattpocockuk·6月19日
An absolute monster PRD, built out from a /decision-mapping session
Love this new flow
https://t.co/mkYXueoJPW
用 /decision-mapping session 生成了一份超详细的 PRD。 很喜欢这个新工作流。
@mattpocockuk·6月19日
Yesterday, I shipped v1 of mattpocock/skills, including:
- /ask-matt: ask me how best to use the skills, from right in your agent
- Model-invoked vs User-invoked skills
- /writing-great-skills, which encodes my skill-writing best practices
Enjoy: https://t.co/7PcrO9rfS3

昨天发布了 mattpocock/skills v1,包含: - /ask-matt:在 agent 内直接问我如何最好地使用这些 skills - Model-invoked 与 User-invoked skills 的区分 - /writing-great-skills:编码了我的 skill 编写最佳实践 欢迎使用。
@mattpocockuk·6月19日
Folks who are running GLM 5.2, how are you doing it?
What harness/provider are you using?
Getting FOMO about an open weights model for the first time
正在跑 GLM 5.2 的朋友们,你们是怎么做的? 用的什么 harness/provider? 这是我第一次对一个开源权重模型产生 FOMO
@mattpocockuk·6月18日
My latest favourite stack is GitHub Actions + Sandcastle + Claude Code
Label an issue, get an implementation
Also works for multi-step PRD's, here's one working live:
https://t.co/yXefmI1IM6
最近最喜欢的 stack:GitHub Actions + Sandcastle + Claude Code 给 issue 打上标签,自动获得实现。 也支持多步骤 PRD,这是一个正在运行的示例:
@mattpocockuk·6月18日
RT @DavidOndrej1: Matt Pocock just explained why everyone is obsessing over the wrong thing
it's not the model, it's the harness
watch th…
Matt Pocock 刚刚解释了为什么大家都在关注错误的东西—— 不是模型,是 harness(编排层)
@mattpocockuk·6月18日
Playing around with the idea of decision maps
1. Figure out the 'frontier' of decisions with a short grilling session
2. Fan out to multiple grilling/prototyping/research sessions, uncovering the fog of war as you go
Here I go, grilling on three aspects of a huge build: https://t.co/KRy6tqILwA

在玩一个「决策地图」的想法: 1. 通过简短的追问环节找出决策的「边界层」 2. 展开多个并行的追问/原型/研究 session,逐步驱散迷雾 实录:同时对一个大项目的三个方面展开追问:
@mattpocockuk·6月18日
Let me put this more simply:
Skills need to be able to import other skills without imposing a token cost
@mattpocockuk
A frustrating gap I'm hitting in the skills spec. TL;DR: I want three tiers of 'invocable'. User-invocable, skill-invocable, and model-invocable. Skill-invocable skills are only invocable by the user, or by skills. Skills can be marked as model-invocable or user-invocable. Model-invocable skills put their description into context. User-invocable skills are hidden from the model, so no tokens are burned on the description. But what about skills that you want to BOTH invoke on their own (user-invocable only), but also use as parts of other skills? An example would be a /review skill, which: 1. Runs some automated checks on the repo 2. Checks the code against the original spec 3. Checks it against some coding standards What if you want to pull out step 1 into its own skill? /run-automated-checks You'd create that skill, then reference it in the /review skill: "1. /run-automated-checks" In order to move that into its own skill, you MUST make it model-invocable - meaning its description goes into context. This is pointless token waste. You can't omit the description - that goes against spec. But you'd just write a description saying "never invoke this except in other skills". Anyone working on the skills spec? Has this been considered?
简单说就是: Skill 必须能引用其他 skill,且不产生额外的 token 开销。 【引用原文】 Skills spec 里我碰到了一个让人抓狂的 gap。 TL;DR:我想要三种「可调用」层级——用户可调用、skill 可调用、model 可调用。Skill 可调用的 skill 只能被用户或其他 skill 触发。 Skill 可以标记为 model-invocable 或 user-invocable。Model-invocable 的 description 会注入 context;user-invocable 对 model 不可见,不消耗 token。 但问题来了:如果一个 skill 既想独立使用(user-invocable),又想作为其他 skill 的子步骤,该怎么办? 比如 /review skill: 1. 跑自动化检查 2. 对照原始 spec 审查代码 3. 对照编码规范审查 如果把第 1 步拆成独立的 /run-automated-checks,你就必须把它设为 model-invocable——description 就进了 context。 这是无意义的 token 浪费。你不能省略 description(违反 spec),又只能写一句「除非在其他 skill 里调用,否则永远不要触发」。 有人在做 skills spec 吗?这个问题考虑过吗?
@mattpocockuk·6月17日
/teach now creates reusable components which get improved/developed as you learn more
More token-efficient, and builds momentum
Look at these sweet cubes: https://t.co/IpHZs6Zsd9
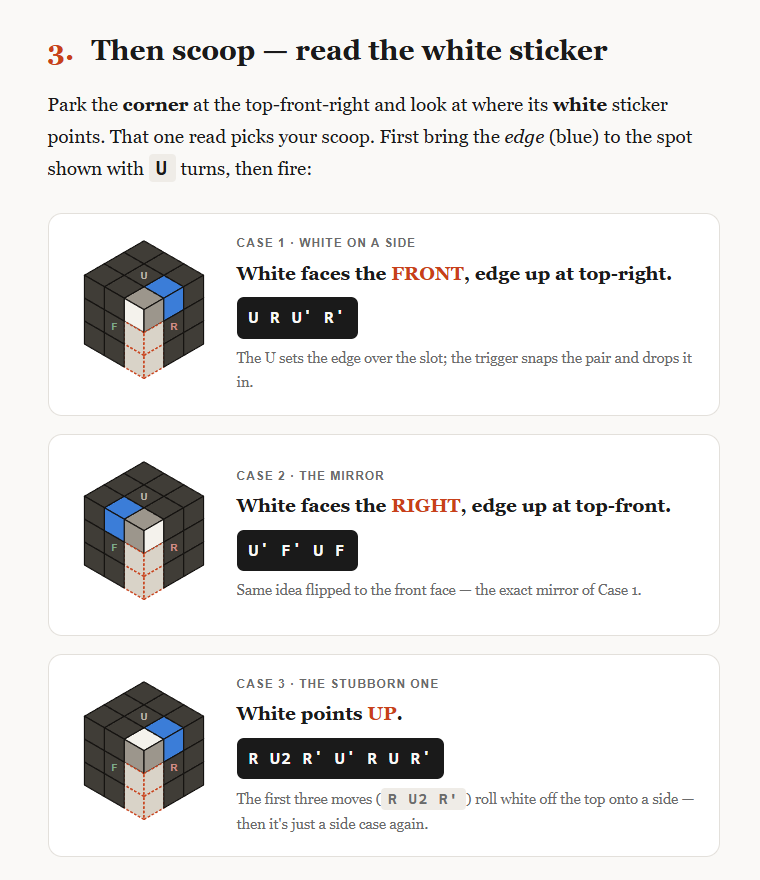
/teach 现在会创建可复用组件,随着你学习的深入持续改进和演化。 更节省 token,也能积累学习动力。 看看这些漂亮的方块:
@mattpocockuk·6月17日
Dex has been very influential on how I work with agents.
Great to have a coding platform fighting the good fight against slop
@dexhorthy
At HumanLayer, we’re on a mission to solve the AI slop code problem. In 2025 we open-sourced our Research, Plan, Implement framework, now deployed inside fortune 500s like Block and Uber - places where shipping slop is just not an option And that was just the beginning. Today, we’re opening access to HumanLayer - an Agentic IDE, collaboration platform, and building blocks for your software factory. HumanLayer enables engineers solving hard problems in complex codebases to: > move 2-3x faster across the entire SDLC (not just coding) > maintain rigorous standards for system architecture and program design Hundreds of engineers at companies of all sizes are already using HumanLayer to ship fast without sacrificing quality. I'm excited to invite you to try humanlayer today at https://t.co/cQ648EkrnG, and I'm even more excited to see what you build. @0xblacklight and I are deeply grateful to our team, our customers who give us so much incredible energy and feedback, our investors who have always been in our corner, and our friends and family who have supported us along this crazy journey if you're a staff or principal engineer trying to make AI coding work at scale for your team, we'd love to hear from you as @swyx likes to say - let's make this the year of no more slop
Dex 对我与 agent 的协作方式影响很大。 很高兴有一个编码平台在认真对抗 slop(AI 生成的低质量代码)。 【引用 @dexhorthy】在 HumanLayer,我们的使命是解决 AI slop 代码问题。 2025 年我们开源了 Research、Plan、Implement 框架,如今已在 Block、Uber 等财富 500 强内部部署——这些地方根本不能容忍发布 slop。 今天,我们正式开放 HumanLayer——一个 Agentic IDE、协作平台与软件工厂构建模块。 HumanLayer 帮助在复杂代码库中解决硬问题的工程师:在整个 SDLC 中提速 2–3 倍(不只是编码),同时维持严格的系统架构与程序设计标准。 各规模公司的数百名工程师已在使用 HumanLayer 实现快而不烂地交付。
@mattpocockuk·6月17日
Announcing mattpocock/skills v1
- Achieved a 63% reduction in token cost for skill descriptions
- Split skills into model-invocable and user-invocable skills, adding /codebase-design, /domain-modeling, and /grilling
- (UPDATED) /writing-great-skills - rewritten from the ground up, encoding my skill-writing best practices
- (UPDATED) /diagnose -> /diagnosing-bugs - now model-invocable, awesome for fixing hard bugs
- (NEW) /ask-matt: a router skill that teaches you how all the engineering skills work together

发布 mattpocock/skills v1 - token 描述成本降低 63% - 将 skills 拆分为「模型可调用」和「用户可调用」两类,新增 /codebase-design、/domain-modeling、/grilling - (更新)/writing-great-skills——从头重写,沉淀了我的 skill 写作最佳实践 - (更新)/diagnose → /diagnosing-bugs——现在改为模型可调用,修 hard bug 效果极佳 - (新增)/ask-matt:一个路由 skill,教你所有工程类 skills 如何配合使用
@mattpocockuk·6月16日
Anthropic has opted against slashing AFK/third-party usage, at least for now
Go back to sleep, Codex, I don't need you yet https://t.co/SXm6ivjw5z

Anthropic 决定暂时不削减 AFK(挂机)/ 第三方使用配额。 回去睡吧 Codex,我暂时还不需要你。
@mattpocockuk·6月15日
I have a deep distrust of almost any 'self-improvement' loop in coding agents
I.e. automatically created memories, CLAUDE.md suggestions applied after every session
Often the suggestions themselves are shit
But even if they're good, the agent often over-indexes on them in a way that's super unhelpful.
It makes the agent impossible to steer. And often because these memories are scoped per-project, each project is unsteerable in its own way.
What's the right name for this? Instruction rot?
我对几乎所有编程 agent 的「自我改进」循环都深表怀疑。比如自动创建记忆、每次会话后自动应用 CLAUDE.md 建议这类机制。这些建议本身往往质量很差。即便是好建议,agent 也会对其过度依赖,变得极难引导。而且这些记忆通常是按项目隔离的,结果每个项目都以自己独特的方式变得不可控。这种现象该叫什么?「指令腐烂(instruction rot)」?
@mattpocockuk·6月15日
Cooking a /decision-mapping skill, for splitting planning into multiple sessions
Kind of like /to-issues, but for planning
Should make greenfield builds + complex brownfield builds much more seamless
正在开发一个 /decision-mapping skill,用于把规划拆分到多个 session 中进行。 有点像 /to-issues,但专注于规划阶段。 应该能让 greenfield 项目构建和复杂的 brownfield 改造流程顺畅很多。
@mattpocockuk·6月15日
Initial thoughts here is that you often need to plan in multiple phases, often in parallel.
So you need a multi-session plan, but for _planning_ as well as for implementation.
An asset that tells you how to plan the feature, so you're not doing the usual /grill-with-docs -> /handoff -> /prototype dance
@mattpocockuk
Here are my 7 phases of AI-powered development. I've been thinking that the pre-PRD phase needs more structure. You need to figure out the shape of the design tree first, before then walking down it with higher-fidelity prototypes. In other words, /grill-with-docs needs to change again IMO
现在的想法是:规划往往需要多阶段并行推进。所以你需要一份多会话计划——不光针对实现,也针对规划本身。一份告诉你「如何规划这个功能」的资产,这样就不用每次都走 /grill-with-docs → /handoff → /prototype 这套流程。 [引用] 我总结了 AI 辅助开发的 7 个阶段。我认为 PRD 之前的阶段需要更多结构——需要先搞清楚设计树的形状,再用更高保真度的原型沿树往下走。换句话说,/grill-with-docs 在我看来需要再次进化。
@mattpocockuk·6月15日
Here are my 7 phases of AI-powered development.
I've been thinking that the pre-PRD phase needs more structure. You need to figure out the shape of the design tree first, before then walking down it with higher-fidelity prototypes.
In other words, /grill-with-docs needs to change again IMO
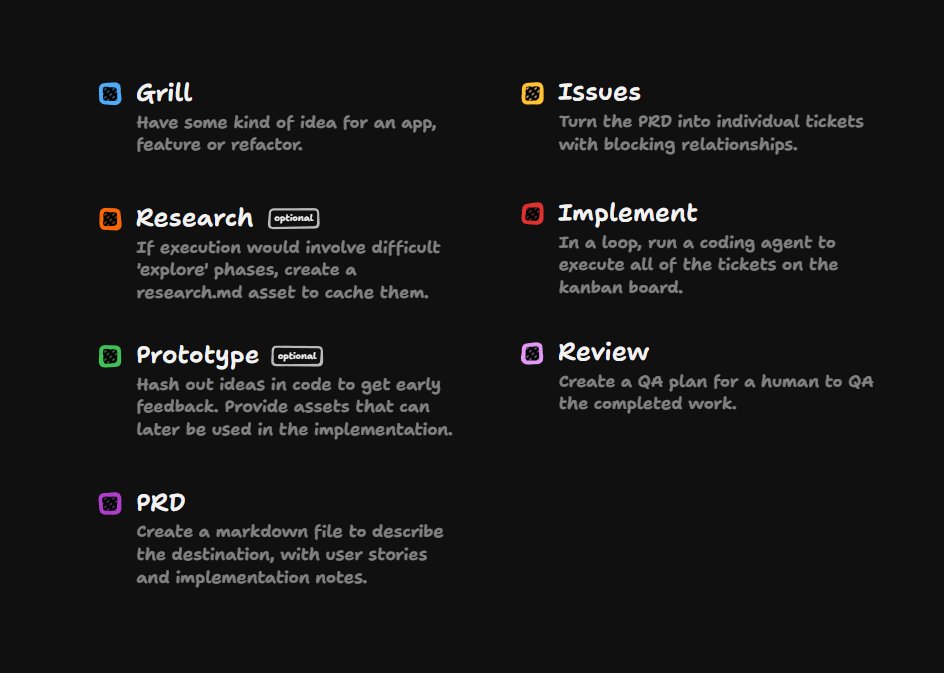
以下是我总结的 AI 赋能开发的 7 个阶段。 我一直在思考,PRD 之前的阶段需要更多结构。你需要先搞清楚设计树的形状,然后再用更高保真度的原型逐步深入。 换句话说,/grill-with-docs 这个环节还需要继续演进。
@mattpocockuk·6月13日
Fable back in the stable
Looks like my "I'll see it how it shakes out" approach to model assessment wins again
Fable 回笼了。 看来我「静观其变」的模型评估方式再次胜出。
@mattpocockuk·6月12日
Seeing a subagent spawn its own subagent is unbelievably satisfying
Subagents are good now
看到一个 subagent 自己又 spawn 出子 subagent,满足感爆棚。 Subagent 现在真的强了。
@mattpocockuk·6月11日
Trying out my /teach skill today, imagining I was a vibe coder wanting to learn the basics.
Here are the four lessons it created so far:
1. It interrogated me on my mission - the reason why I wanted to learn vibe coding. I said I was a teacher wanting to build a scheduling app.
2. Started me off with git so I had the ability to roll back bad work. Just 5 basic commands. No rebasing/merging yet. Perfect.
3. Taught me the basic units of a full-stack app: frontend, backend, auth and database. Every example was tied to the app I wanted to build. Quiz at the end.
4. I didn't choose a stack preference, but it noticed Node was already installed! Clever agent. So it chose Next.js and Supabase as my stack, and taught me hot reload. I got commands to set up my app.
Each day sent me off to primary sources to verify that what I was learning was true. Git docs, AWS articles, Next.js docs.
This is addictive, personalized, and infinite. Give it a go.
今天我亲自试用了自己开发的 /teach skill,假装自己是个想学基础知识的 vibe coder。 以下是它目前为止创建的四节课: 1. 它先审问了我的目标——我为什么想学 vibe coding。我说我是一名老师,想开发一个排课应用。 2. 从 git 开始入手,让我具备回滚错误操作的能力。只有 5 个基本命令,没有 rebase/merge。恰到好处。 3. 教我全栈应用的基本单元:前端、后端、auth 和数据库。每个例子都围绕我想做的那个应用展开。最后有测验。 4. 我没有指定技术栈偏好,但它发现 Node 已经安装了!很聪明的 agent。于是它选了 Next.js 和 Supabase,并教我了热重载,还给了我初始化项目的命令。 每天它都让我去一手资料验证所学内容:Git 文档、AWS 文章、Next.js 文档。 这种体验令人上瘾、高度个性化,而且是无限的。去试试吧。
@mattpocockuk·6月11日
Instead of waiting for a new model to fix your problems
Why not just fix your problems
与其等下一个新 model 来解决你的问题,不如直接把问题解决掉。
@mattpocockuk·6月10日
I think I might move the /teach skill to a new repo
It's not really about engineering, and it deserves a bigger treatment:
- 100 example prompts you can use with /teach
- Guides and docs on the underlying principles behind it
我在考虑把 /teach skill 迁移到一个独立 repo。 它其实和工程没太大关系,值得做更系统的整理: - 100 个可以配合 /teach 使用的示例 prompt - 背后设计原则的指南和文档
@mattpocockuk·6月10日
/teach now recommends primary source reading in every lesson
The goal isn't to keep you shackled to the agent, it's to get you confident enough to read the sources for yourself https://t.co/ddvcMn4MwK

/teach 现在会在每节课末尾推荐一手资料阅读 目标不是让你一直被绑在 agent 上,而是帮你建立足够的信心,自己去读原始文档
@mattpocockuk·6月10日
Steps to become a senior programmer:
1. Install my /teach skill
npx skills add mattpocock/skills --skill teach
2. Create a new working directory on your laptop
mkdir junior-to-senior
cd junior-to-senior
3. Kick off your coding agent in the directory
claude
4. Copy this prompt
/teach me how to be a great strategic programmer. My opinion is that AI is eating 'tactical, on-the-ground' programming. The day-to-day work of a developer involves not only coding, but also planning, QA, codebase design, and much more. I'm interested in learning the strategic skills - that, in a previous era, would take me from junior to senior - but in this era are table stakes.
5. Paste it into the coding agent
Below is an example of what the first output will look like. I used Opus 4.8, medium effort.
6. Continue working with the agent until you're a senior

成为高级程序员的步骤: 1. 安装我的 /teach skill npx skills add mattpocock/skills --skill teach 2. 在本地创建工作目录 mkdir junior-to-senior && cd junior-to-senior 3. 在该目录启动 coding agent claude 4. 复制这个 prompt: /teach me how to be a great strategic programmer. 我的观点是 AI 正在蚕食「战术性、一线」编程。开发者的日常不只是写代码,还包括规划、QA、代码库设计等。我想学习那些战略性技能——在以前的时代,这些是从初级晋升到高级的必经之路——但在这个时代,它们已经是基本门槛。 5. 粘贴到 coding agent 并开始 以下是第一次输出的示例(使用 Opus 4.8,medium effort)。 6. 持续与 agent 协作,直到你成为高级开发者
@mattpocockuk·6月9日
Of all the things I've tried to get good at, teaching has been the most rewarding
Figuring out the best way to compress knowledge and fit it in people's heads in an engaging way is a puzzle that never ends
Every course I teach, I get better, but there is always headroom
在我尝试精进的所有事情中,教学是最有回报的。 搞清楚如何以最佳方式压缩知识、以引人入胜的形式装进人们脑子里,是一个永无止境的谜题。 我每教一门课都会进步,但永远还有提升空间。
@mattpocockuk·6月9日
Everyone's banging on about loops
When they should be thinking about queues
大家都在聊 loops(循环), 其实应该想想 queues(队列)。
@mattpocockuk·6月9日
RT @EddyVinckk: I set up Sandcastle by @mattpocockuk recently
It is in my opinion the most ergonomic tool out there to run sandboxed agen…
最近配置了 @mattpocockuk 的 Sandcastle 在我看来,这是目前运行沙盒 agent 最符合人体工学的工具……
@mattpocockuk·6月9日
Experimenting today with:
- /to-prd to create a PRD
- /goal to implement
- "autoCompactWindow": 180000 to stay approximately in the smart zone
Let's see how it goes.
今天在实验: - /to-prd 生成 PRD - /goal 来驱动实现 - "autoCompactWindow": 180000 让 context 大致保持在智能区间 看看效果如何。
@mattpocockuk·6月8日
/teach is live
Learn anything, from rubik's cube to vocal harmonies to software fundamentals.
npx skills add mattpocock/skills --skill teach
Best skill I've ever built, video coming soon
https://t.co/GAv1jBFwsX
/teach 上线了 学任何东西——从魔方到声乐和声再到软件基础。 npx skills add mattpocock/skills --skill teach 我做过最好的 skill,视频即将发布
@mattpocockuk·6月5日
Roadtesting my /teach skill by seeing if it can teach me to solve a Rubik's cube
I like it so much I've ordered a speed cube https://t.co/k5V60WCy9u

用我的 /teach skill 做了个路测,看它能不能教我解魔方 太喜欢了,已经下单了一个速解魔方 🎲
@mattpocockuk·6月5日
Everyone knows the "AI" label is bullshit. So how do you define it?
Here's how I did it in my upcoming AI coding dictionary:
"A moving label, not a technology. Points at whatever computers can newly, impressively do — right now, large language models." https://t.co/78vYh3aVo4

大家都知道「AI」这个标签其实没什么实质含义。那怎么定义它? 这是我在即将出版的 AI 编程词典里的定义: 「一个动态标签,而非一种技术。它指向计算机最新的、令人印象深刻的能力——当下,就是大型语言模型。」
@mattpocockuk·6月5日
A context engineering metaphor I've been playing around with:
- Primary source: the source of truth. Raw data. Transcripts. Code.
- Secondary source: one step removed. Summaries. Compactions. Documentation.
For instance, compaction takes a primary source (the conversation history) and turns it into a secondary source (the summary). This is lossy, but means the secondary source can fit into a smaller space.
If you want to know what your codebase does, your code is a primary source. Your docs are a secondary source.
Loading primary sources into context is expensive, but provides richer context. Secondary sources are cheaper to load into context, but may be information-lossy.
Any context engineering will involve managing the tradeoffs between both.
我一直在思考的一个 context engineering 比喻: - 一次来源:真相之源。原始数据。对话记录。代码。 - 二次来源:经过一层处理后的产物。摘要。Compaction。文档。 例如,compaction 将一次来源(对话历史)转化为二次来源(摘要)。这是有损的,但意味着二次来源能装进更小的空间。 如果你想了解代码库的功能,代码是一次来源,文档是二次来源。 将一次来源加载进 context 代价高昂,但提供更丰富的上下文。二次来源加载更便宜,但可能造成信息损失。 任何 context engineering 都涉及在这两者之间做权衡。
@mattpocockuk·6月4日
Thinking about a /grill-prep skill
The idea being to do a light grilling of your idea, then break out the areas of discussion into separate threads.
Would help prevent the problem of "I hit the dumb zone during grilling, help!"
在想一个 /grill-prep skill 思路是先对你的想法做轻量级 grill,然后把讨论领域拆分成独立 thread。 可以解决「grill 过程中进入 dumb zone 完全失去状态」的问题。
@mattpocockuk·6月4日
Preview of an AI Coding Dictionary I'm shipping later this month
AI coding sounds complex (harness, model, agent, tool etc) but it's really not. You just need to understand the terms of engagement.
@vojta_holik
knowledge has a shape https://t.co/drPp3rM8lF
预告:我本月晚些时候将发布一本 AI 编程词典。 AI 编程听起来很复杂(harness、model、agent、tool 等),但其实并没有那么难。你只需要搞懂这些术语的含义。 [引用 @vojta_holik]:知识是有形状的
@mattpocockuk·6月4日
RT @_smontlouis: /improve-codebase-architecture
j'ai rarement vu un skill aussi merveilleux
/improve-codebase-architecture 我很少见过如此精彩的 skill
@mattpocockuk·6月3日
Playing around with a Kent Beck-inspired prompt today:
Before implementation, look for opportunities to prefactor the code to make the implementation easier. "Make the change easy, then make the easy change."
今天在玩一个受 Kent Beck 启发的 prompt: 在实现之前,先寻找机会对代码进行「预重构」,让实现变得更容易。「先让改动变得容易,再做那个容易的改动。」
@mattpocockuk·6月3日
Idea for a skill distribution mechanism for JS/TS teams:
1. Create an npm package with your skills
2. On postinstall for that package, run a script that symlinks them to .claude/skills
Simple, versioned, intuitive skill distribution
Any reason this wouldn't work?
给 JS/TS 团队分发 skill 的思路: 1. 把你的 skill 打包成一个 npm 包 2. 在该包的 postinstall 脚本里,把 skill symlink 到 .claude/skills 简单、有版本管理、直觉友好的 skill 分发机制。 有什么理由说这行不通吗?
@mattpocockuk·6月2日
Would you guys dig a /resolve-merge-conflicts skill?
It's another one of those that I have a prompt for, but just haven't turned it into a skill yet.
大家对 /resolve-merge-conflicts skill 感兴趣吗? 这是我手头有 prompt 但还没包装成 skill 的一个工具——想听听大家的意见。
@mattpocockuk·5月31日
So every time I say the word 'workflow' in Claude Code...
(let's say, when I'm creating a new GitHub workflow)
...it tries to enter 'workflow' mode, spinning up dozens of subagents to complete my task.
Stupid fucking thing
所以每次我在 Claude Code 里说 'workflow' 这个词…… (比如创建一个新的 GitHub workflow) ……它就会进入 'workflow' 模式,启动几十个 subagent 来完成我的任务。 蠢透了
@mattpocockuk·5月29日
Writing ADR's for agents has been such a good decision
Capturing all the non-obvious decisions in a codebase makes every agent in your stack that touches the stack smarter
It's the thinnest layer of docs that captures the stuff code can't
给 agent 写 ADR(架构决策记录)是个极好的决定。 把代码库中所有非显而易见的决策记录下来,能让你整个 agent 栈里接触这个代码库的每一个 agent 都变得更聪明。 这是最薄的一层文档,却捕捉了代码本身无法表达的东西。
@mattpocockuk·5月29日
One thing people underrate about the smart zone:
It's a great way to save on tokens.
When you're in the dumb zone, sending 600K tokens on every request gets expensive FAST
Yes, you get charged for cache hits. Less, but it still adds up.
有一件被严重低估的事情:smart zone 是省 token 的好方法。 当你处于 dumb zone 时,每次请求发送 60 万个 token,成本会飞速累积。 是的,cache hit 也要收费——虽然少一些,但仍然在叠加。
@mattpocockuk·5月28日
An interesting idea that I've not heard expressed anywhere (but I'm sure is not original)
The fewer test seams you have in your app, the better
Agents are incredibly good at problems where there is a single test seam. Building a language, reimplementing a pure library.
You test from the outside (by invoking the library, or running the language) and you check the results. Any further tests are added at that single seam.
But when there are more seams, like:
- Tests that test only a single function
- Test that test a group of modules, and mock others
Then the agent is incentivised to add more and more seams.
The more seams you have, the more coupled the tests are to the underlying implementation. AND the fewer assurances you have that the whole system works together.
But some apps don't respond well to single-seam testing. Are you going to run your entire app with every service mocked just to run a single test?
So you can't always reduce it to a single seam. But it seems (haha) to me that the fewer seams, the better.
WDYT?
一个我没见别人表达过的有趣观点(虽然肯定不是原创):app 里的测试接缝越少越好。 Agent 在只有单一测试接缝的问题上表现极好——比如构建一门语言、重实现一个纯函数库。从外部测试(调用库或运行语言),检查结果。所有额外测试都加在那个唯一的接缝上。 但当接缝变多时——比如只测单个函数的测试、mock 掉其他模块的集成测试——agent 就会被激励去添加越来越多的接缝。接缝越多,测试与底层实现的耦合越紧,对整体系统协同运行的保障也越少。 但有些 app 本来就不适合单一接缝测试。难道要 mock 所有服务跑完整个 app 才能运行一个单测吗? 所以并不总能简化到单一接缝。但在我看来,接缝越少越好。 你怎么看?
@mattpocockuk·5月28日
Cursor shipped a /thermo-nuclear-code-review for the TOUGHEST AI code review possible.
But is it any good? Let's dive in: https://t.co/KbYDIh4qQ1

Cursor 推出了 /thermo-nuclear-code-review,号称最严酷的 AI 代码审查。 但它真的好用吗?来深挖一下:[链接]
@mattpocockuk·5月22日
Uncle Bob gets it
@unclebobmartin
I am absolutely more productive using agents. I don't know the factor but it's large. However much of that productivity is spent tuning the agents and hardening the product. I'm guessing 30%-40%. Some might consider that a waste; but I don't. The software I'm creating nowadays is vastly more robust than I'd ever been able to create manually. I don't mean that the code is better. I mean the surrounding tests are vastly better. I have a higher degree of confidence than I ever had manually -- even when I used very disciplined TDD and Acceptance testing. And then there's the ability to quickly reorganize the modules and the architecture while keeping those robust tests running. That is a tremendous boon.
@mattpocockuk: Uncle Bob 说到点子上了 [引用 @unclebobmartin]: 用 agent 确实让我生产力大幅提升,具体倍数说不清,但很显著。不过其中 30%-40% 的生产力都花在了调优 agent 和加固产品上。有人可能觉得这是浪费,但我不这么看。我现在写出来的软件,比以前手动写的要健壮得多。 我说的不是代码本身更好,而是周边的测试套件质量远超从前——哪怕是我曾经认真践行 TDD 和验收测试的时候,我也没有现在这种信心。 还有一个巨大的好处:能在保持这套健壮测试运行的前提下,快速重组模块和架构。这真是莫大的红利。
@mattpocockuk·5月22日
Another layer of documentation I'm considering (along with CONTEXT.md and ADR's) is a list of all the agreed test seams in the app
Agents simply cannot be trusted to make good decisions about what to test, and at what seam.
For every small change, they extract out only what they've built into a testable function and test that.
It leads to a patchwork nightmare of tests that break as soon as the implementation changes.
我在考虑的另一层文档(与 CONTEXT.md 和 ADR 并列):列出应用中所有**约定好的测试边界**。 Agent 根本不可信——它们没有能力对「测什么、在哪个层测」做出好的判断。每次小改动,它们只会把自己刚写的东西抽成一个可测函数然后测它。结果就是一堆东拼西凑的测试,实现一变全挂。
@mattpocockuk·5月21日
Hooking up /improve-codebase-architecture so it pings me a suggestion every morning at 9AM
Agents are fun
把 /improve-codebase-architecture 接上了定时任务,每天早上 9 点推一条架构改进建议。 Agent 真好玩。
@mattpocockuk·5月21日
You asked for it, so here it is: a deep-dive on my new /handoff skill.
It's an alternative to /compact that gives you WAY more flexibility with your context window.
- Think of an idea, handoff to another agent to implement
- Grill, handoff to prototype, handoff BACK
Enjoy: https://t.co/V5oVe4QjiK

应大家要求,来了:深度解析我的新 /handoff skill。 这是 /compact 的替代方案,让你在管理 context window 时拥有更多灵活性。 - 想到一个 idea,handoff 给另一个 agent 去实现 - 先让 agent 死磕追问(grilling),再 handoff 给原型 agent,再 handoff 回来 享用吧:https://t.co/V5oVe4QjiK
@mattpocockuk·5月21日
Adding a tweak to the /tdd skill:
"Do not add tests which simply restate the implementation. These provide zero confidence."
Getting sick of shit tests just to provide evidence of RGR.
给 /tdd skill 加了一条规则: 「不要写那些只是把实现逻辑重新陈述一遍的测试。这种测试毫无置信度。」 受够了那些只为了跑完 RGR 流程而凑数的垃圾测试。
@mattpocockuk·5月20日
Tactical vs Strategic Programming, and why I'm nervous for juniors:
Good programming involves a mix of tactical and strategic decision-making:
- Tactical: on the ground, short-term. The soldier doing the fighting.
- Strategic: high-view, long-term. The general planning the war.
You need to be a tactician to write good code. To choose the right syntax. To figure out the file structure. To figure out how best to test your changes.
But you need to be a strategist to build code that lasts. To design the architecture. To automate away problems. To think beyond today.
Agents have eaten the tactical part of programming. When you can pay below minimum wage for code, there's no point going into the trenches yourself.
But AI cannot code strategically. Agents need someone at the top of the pyramid to tell them what to do. They need oversight.
So, a developer's day-to-day job has become 100% strategy. Long-term thinking, all the time. (maybe this is why I'm so tired all the time now)
If you identify as a tactical programmer - a code monkey - then you are out of luck. The job has changed.
Personally, I like it. I always preferred thinking strategically about code. If you asked me what my job was about, I'd say 'building apps', not 'writing code'.
But what makes me nervous is that we've pulled down the only bridge that brought juniors into the industry.
We used to train juniors like this:
1. Give them only tactical tasks
2. Let them build up their strategic experience slowly
Eventually, they are a good enough strategist that they are no longer a junior.
But what happens when all tactical code is written by AI? What is the point of a junior?
We obviously need juniors. We need new lifeblood coming into the industry. We need to leave paths open for extraordinary hires to enrich our companies.
But how do we train them? How do you train strategic thinking?
These are the questions I'm thinking about. I'd love to know your thoughts.
战术 vs 战略编程,以及我为初级工程师的担忧: 好的编程需要战术和战略决策的结合: - 战术:一线、短期。像打仗的士兵。 - 战略:高视角、长期。像规划战争的将军。 成为好的战术家,才能写出好代码——选对语法、确定文件结构、找到最佳测试方式。 成为好的战略家,才能构建经得住时间的代码——设计架构、自动化解决问题、着眼长远。 Agent 已经吃掉了编程的战术部分。当代码成本低于最低工资时,自己下壕沟就没有意义了。 但 AI 无法做战略性编程。Agent 需要有人在金字塔顶端指挥,需要人类监督。 所以,开发者的日常已经变成 100% 战略——全程长期思考。(也许这就是我一直很累的原因) 如果你把自己定位为战术程序员——代码工具人——那你就麻烦了。这份工作已经变了。 就我个人而言,我喜欢这个变化。我一直更倾向战略性地思考代码。如果你问我的工作是关于什么的,我会说「构建应用」,而不是「写代码」。 但让我担忧的是:我们拉断了曾经将初级工程师带入这个行业的唯一桥梁。 过去我们这样培训初级工程师: 1. 只给战术任务 2. 让他们慢慢积累战略经验 最终,战略能力足够强,不再是初级工程师。 但当所有战术代码都由 AI 编写时,会发生什么?初级工程师的意义在哪里? 我们显然需要初级工程师——需要新鲜血液,需要为非凡人才留下成长路径。 但我们如何培训他们?如何训练战略思维? 这是我正在思考的问题,很想听听大家的想法。
@mattpocockuk·5月19日
Clearly Antigravity is not SOTA, still using /grill-me and not /grill-with-docs
Side note - pretty wild to see a skill I cooked up being used in a Google product demo
@antigravity
Introducing Antigravity 2.0, a new standalone desktop application that delivers fully on that original glimpse of a truly agent-optimized experience. Rebuilt from the ground up with multi-agent teams, scheduled tasks, native voice and one-click integration with other Google products. Learn how to get started with Antigravity 2.0 👇
Antigravity 显然不是 SOTA——居然还在用 /grill-me 而不是 /grill-with-docs 顺带一提,看到自己写的 skill 出现在 Google 产品 demo 里,感觉挺魔幻的 【引用】Antigravity 2.0 发布——一款全新的独立桌面应用,真正兑现了最初对 agent 优化体验的设想。从零重建,支持 multi-agent teams、定时任务、原生语音,以及一键集成其他 Google 产品。
@mattpocockuk·5月19日
Making implementation cheaper has made creating bad code cheaper
But it's also made creating good code cheaper
You just need to know the difference
让实现变便宜,也让写烂代码变便宜了 但同样,让写好代码也变便宜了 你只需要知道两者的区别
@mattpocockuk·5月19日
Considering an /auto-grill skill which you'd run during a grilling session
1. Run when you feel like you and the agent are on the same page
2. It continues the grilling but always accepts its own recommendation
3. If you disagree, you manually interrupt it
Worth a try?
考虑做一个 /auto-grill skill,在 grilling session 中使用: 1. 当你感觉自己和 agent 已经在同一频道时运行 2. 它继续 grilling,但始终接受自己的建议 3. 如果你不同意,手动打断 值得一试?
760 tweets · 188 sources